







Artificial Intelligence
GeoVodcast #1: Spatial Inequalities in Deprived Urban Areas
34:21
Remote sensing involves analysing vast amounts of Earth Observation (EO) data, typically acquired from satellite data, aircraft or Unmanned aerial vehicles (UAVs). Machine learning models can be trained to assist here, by automatically classifying land use and land cover, identifying vegetation cover, determining soil types, detecting changes in the landscape, and more.
Deep learning models in particular have proven to be successful in addressing Earth science challenges due to their ability to capture the non-linear patterns inherent in EO data. However, deep learning models require a considerable amount of labelled data to obtain good generalization capability, as labelled data provide the necessary examples of what the model needs to identify in new, unseen data.
In labelled data, each data point is associated with a label or tag that indicates its category, class, or some other relevant attribute. These labels provide supervised information to machine learning algorithms during the training process. Essentially, labelled data pairs input data with the correct output, allowing machine learning models to learn patterns and relationships between input features and their corresponding labels.
Collecting large amounts of either field data or manually annotated data is complicated from an operational viewpoint. Deep learning models often have millions of parameters and therefore require a sufficient amount of data to successfully train the architecture. In addition, the quality of the training samples is very important. The samples should be as representative as possible of the whole study area.
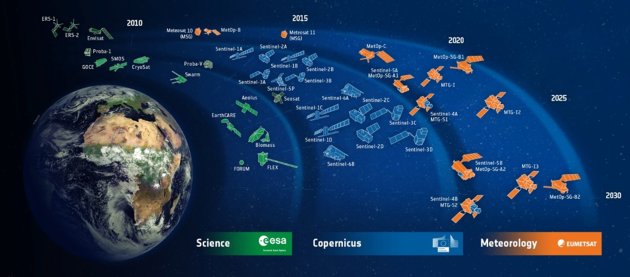 Image source: ESA, CC BY-SA IGO 3.0
Image source: ESA, CC BY-SA IGO 3.0
The unprecedented access to remote sensing data, regularly obtained through public and private Earth Observation Programs and Missions (e.g., ESA Copernicus, NASA/USGS Landsat, PlanetScope, etc.), allow us to perform highly comprehensive environmental analyses. These valuable information sources enable us to understand a wide range of processes on the Earth's surface.
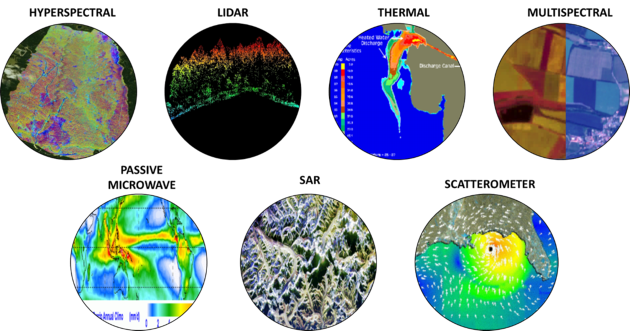
Depending on the type of properties we want to retrieve, we can use different kinds of sensors, such as LIDAR, SAR, multispectral or hyperspectral. The availability of large amounts of multi-source, multimodal information allows us to constantly check what's happening on our planet. During the last few decades, all this information has become increasingly accessible. Many archives now offer totally free remote sensing data.
While big data availability is obviously a good thing, downloading and processing huge amounts of data for performing large scale analyses can be troublesome, because not everyone in our world has access to a high-performance computer. This is where cloud computing has been a godsend. All a researcher needs is a laptop with internet connectivity, and the cloud platform will do the heavy work.
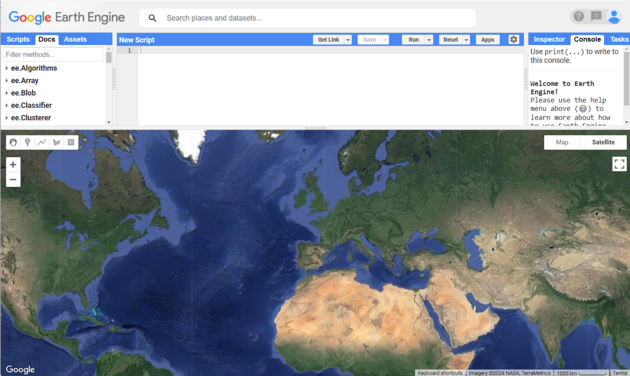
One of the most popular platforms in the remote sensing community is Google Earth Engine. It allows researchers to dig into the archives and retrieve whatever they need without having to download massive amounts of data. In addition, they have cloud computing resources at their disposal, so they can perform large-scale data analyses for environmental monitoring or any other purpose. All it takes is a modest laptop.
The combination of large amounts of multi-source and multimodal data, cloud computing and open archives has certainly helped the earth observation research field. It allows more insight into the dynamic processes that are now occurring on our planet. The bottleneck is the continuous collection of labelled data. Machine learning can help us here, providing that the models are properly trained.
Machine learning – especially deep learning – is totally changing the field of earth observation. The computer vision community has been ahead of the field here, because labelling natural images is more intuitive and requires less effort. However, in the past few years the remote sensing community has been increasingly successful at performing environmental analyses using deep learning algorithms. These results have been greatly helped by many large-scale benchmark data archives having become available in the “benchmark datasets rush” of the past years.

Even though these benchmark datasets are a valuable source of information for training models and comparing methods, it isn’t obvious that they support large-scale operational and environmental analyses in remote sensing. We simply cannot do without sufficient amounts of labelled data.
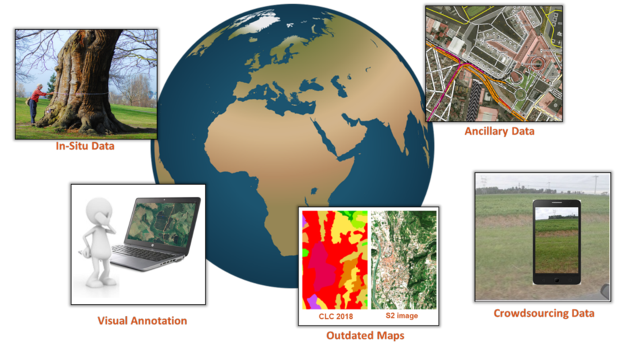
In earth observation, there are several sources of labelled data:
In-situ measurements – information collected directly in the field. This type of labeled data is highly accurate and provides ground truth information but it requires costly and time-consuming field campaigns.
Visual annotation – information provided by experts who typically analyse and annotate Very High Resolution (VHR) images. To this end, reference data collection platforms are increasingly available - for example at the website geo-wiki.org
Outdated maps – information provided by existing historical maps of (parts of) the study area, which can be used as a reference point for generating recent labeled data.
Ancillary data – geospatial data publicly available online such as regional or local administrative databases, population census data, etc..
Crowdsourcing data – geospatial data collected from a large number of non-expert contributors, such as Open Street Map, often through online platforms. Volunteers may be willing to label images, report observations, or contribute with GPS tracks.
Check out our other article on this topic, Four popular sources of labelled data for machine learning.
Several learning paradigms can be of service here, to cite a few:
Transfer learning – a model trained on one task is reused or adapted for a second related task, drastically reducing the need for recent labelled reference data. For further details, see this article, "Recent advances in domain adaptation for the classification of remote sensing data."
Self-supervised learning – the learning process adjusts dynamically based on the complexity of the training samples. This method can make effective use of unlabeled data to mitigate labeled data scarcity. For more information, refer to the article "Self-supervised learning in remote sensing: A review."
Active learning – the model selects and queries the most informative or uncertain samples for labelling, which are then annotated by a human expert. By focusing on these critical samples, the model's accuracy can be improved more rapidly. For more details, see this article, "Active learning methods for remote sensing image classification."
Although deep learning models require large amounts of data to achieve optimal performance, the integration of advanced machine learning paradigms with different data sources offers a powerful solution to this challenge. Techniques such as transfer learning, self-supervised learning and active learning allow us to mitigate and overcome the limitations of labelled data availability effectively. In this way, our deep learning models are trained more effectively, even in data scarcity scenarios.
To learn more, check out the following journal articles:
Login and start learning!

