
Artificial Intelligence
Monitoring urban forests using deep learning
6 min







Machine learning can be helpful to society in a number of ways, but it is known to sometimes propagate unwelcome prejudice. This phenomenon is called machine learning bias, and many people are growing increasingly concerned about it. A well-known case involves facial recognition, which tends to identify people of certain colours better than others. Another example is job application algorithms where women are not selected as often as men, which can be caused by the simple fact that, historically, certain jobs have always received more applications from men than women.
How does machine learning bias affect GIS?
Machine learning techniques are also used with geospatial algorithms, and similar types of biases can come into play here. Biases tend to happen, for example, for reasons such as representation. When we create machine learning techniques, or when we make an algorithm, we select examples of what we are looking for. But sometimes examples of one type are more common than examples of another type. So once the algorithm is run, the same differences occur.
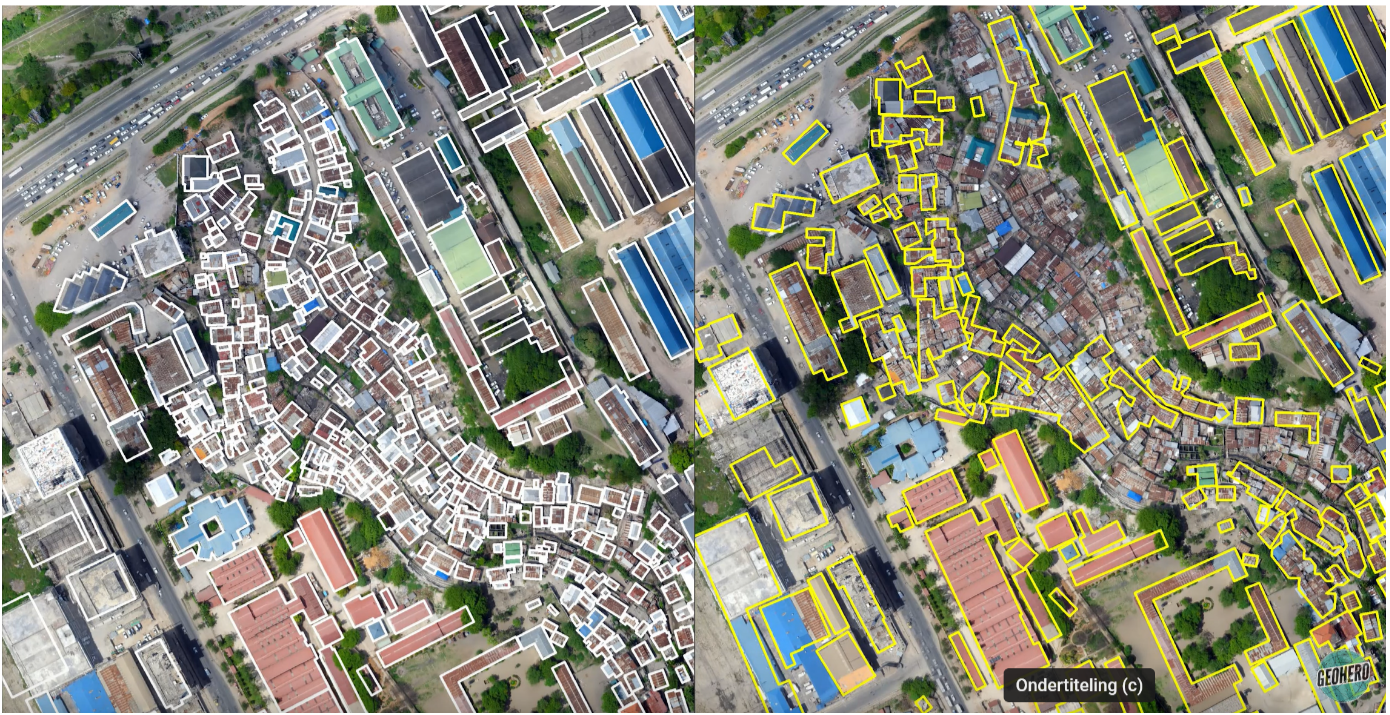
Figure 1 may serve to illustrate the issue in geospatial applications by comparing two different interpretations of one drone image. The image on the left shows, in white, building outlines that were delineated by actual community members. The image on the right, with the yellow outlines, shows results which were published online for free by a major software company a number of years back and supposedly outline all buildings in Tanzania.
When the two images are compared, it’s clear that the algorithm does not work too well in the central part of the image, where the buildings are smaller and closer together. In the top right corner where the buildings are bigger, the algorithm does a better job. In practice, this could mean that the algorithm does not recognize slum areas as such. This is problematic in a number of ways, not least in the case of emergency response situations where it’s vital to know how many people are in certain areas. Such information is indispensable for sending help and distributing resources to the right place. Using biased AI data for mapping could mean that help and resources would not reach those who need them most.
Based on the preceding example, it seems that the machine learning algorithm favours bigger shapes and certain types of roof material. This could certainly be caused by the type of data that is used as input. When we train an algorithm we often use data that’s more commonly available. This isn’t a problem in, for example, the Netherlands, where all building outlines have been readily digitized. In other parts of the world, however, this could be considerably more complicated.
UNESCO is working hard on guidelines, and the European Union is preparing specific legislation. One of the principles will be that every machine learning algorithm that is used – including applications in the geospatial domain – needs to be audited for bias. In anticipation of this, ITC is currently looking into ways to audit algorithms for biases, and to explain the results of algorithms to those who want to use it. Understanding the biases is key if best practices are to be established. Once we truly understand what causes bias and how big the impact is, we can make sure to avoid the problem before it becomes a major societal concern.
If you’d like to learn more about this topic, check out this Geoversity course GeoTechE: Introduction to Geotechnology Ethics
Login and start learning!


{kind=link}